California USA Wrestling sponsors a “Triple Crown Championship Series” in which it gives awards to wrestlers who win three or more state-level tournaments. You can see the details here [link goes to different site].
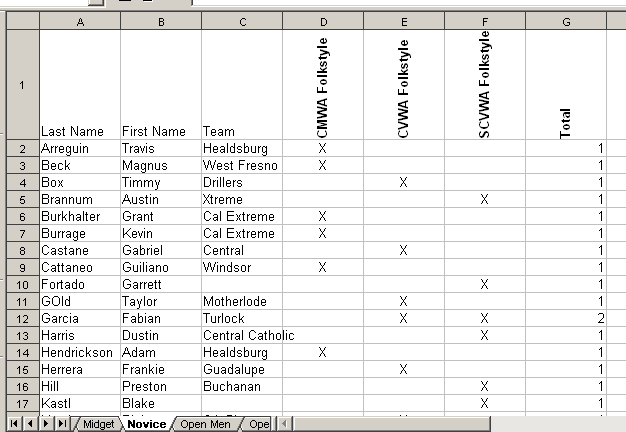
The results from each triple crown qualifying tournament appear on a web page in varying formats; see the San Jose tournament results and the Healdsburg tournament results [these links go to a different site]. As you see, the results are categorized by weight class within age group. For the triple crown, though, we don’t care about the weight class at all. Instead, we need the results organized by tournament within age group, and we need to concern ourselves only with the winners. For each age group, we want a spreadsheet like this:
Since we cannot directly create an Excel file (although it is possible to directly create an OpenOffice.org spreadsheet), we will have to settle for creating a .csv file that uses tabs as field separators on each line.
The first problem is to get all this data and put it in a standard format. This is not done with a Perl program; it’s fairly easy to copy the information from each web page into a text file and use regular expression find-and-replace and a small amount of hand editing to achieve the final format. You can see the San Jose text file and the Healdsburg text file here. The first line in the file is the name of the event, followed by sets of age group and style (lines starting with an asterisk). Each age group consists of a set of weight classes and winner(s) for that weight class.
By adding the asterisks, we split the input into two easily identifiable types of lines. If a line begins with an asterisk, it’s an age group and wrestling style. If it begins with 1., possibly with leading spaces, it’s the name of a first place winner. All other lines can be ignored.
From the spreadsheet, it becomes clear that the data hierarchy, from top down, is age group, event, competitor. The program creates two data structures to hold this information.
The %events hash is a hash of arrays. The key is an age group
name, and the value is an array of the event names for that age group.
The two files shown above produce this hash:
%events =
(
'Midget' => ['SCVWA Folkstyle',
'CMWA Folkstyle'],
'Novice' => ['SCVWA Folkstyle',
'CMWA Folkstyle'],
'Cadet' => ['SCVWA Folkstyle'],
'Schoolboy' => ['SCVWA Folkstyle',
'CMWA Folkstyle']
);
The more complex data structure is %info, which is a
hash of hash of arrays. The key to the main hash is an age group,
and the value is another hash. This second hash
uses a string in the form
lastname:firstname:team as its key,
and has an array of events in which that person has participated.
This array is kept by number corresponding to the position in
the @{%events{$age_group}} so that the program doesn’t
need to duplicate the event names. Here is a portion of the
%info hash from the two sample files:
%info = (
'Midget' => {
'Klee:Paul:Windsor' => [1],
'Prasad:Kyle:Healdsburg' => [1],
'Colunga:Nicholas:Central Catholic' => [0],
'Reynolds:Austin:Fullon Outlaw' => [1],
'Longo:Michael:Cal Extreme' => [1],
'Reyes:Lance:Central Catholic' => [0]
},
'Novice' => {
'Hendrickson:Adam:Healdsburg' => [1],
'Brannum:Austin:Xtreme' => [0],
'Ramos:Tabitha:BAM' => [1],
'Cattaneo:Guiliano:Windsor' => [1],
'Hill:Preston:Buchanan' => [0],
'Linton:Cody:Vacaville' => [0,1],
},
'Cadet' => {
'McCovey:Roger:' => [0],
'Poteete:Nathan:' => [0],
'Rios:Ruben:' => [0],
'Aragon:Everette:' => [0],
'Stebbins:Travis:' => [0],
'Arias:David:' => [0]
},
'Schoolboy' => {
'Amandoli:Lee:Valley' => [1],
'Perlhutter:Jeff:Petaluma' => [1],
}
);
Each entry in the main %info hash (age group)
generates a new file. For each file we do the following:
After outputting a line containing the headers, iterate through
the %{$info{$age_group}} hash. Each entry in that hash
represents the win/no-win record for a single competitor, and creates
a new line in the output file.
The triplecrown.zip file contains the Perl code and several sample data files.